Regardless of your occupation or age, you’ve heard about OpenAI’s generative pre-trained transformer (GPT) technology on LinkedIn, YouTube, or in the news. These powerful artificial intelligence models/chatbots can seemingly handle any task, from creating poems to solving leetcode problems to coherently summarizing long articles of text.

GPT Playground Summarizing Jupiter Notes
The promising applications of GPT models seem endless within the expanding NLP industry. But with ever-increasing model sizes, it is crucial for teams that are building large language models (LLMs) to understand every model’s performance and behaviors. Since AI, like GPT, is a growing subject in ethics, developers should ensure that their models are fair, accountable, and explainable. However, doing proper testing on artificial general intelligence across many different contexts is tedious, expensive, and time-consuming.
This article offers an extensive guide to using GPT models and compares their performance for the abstractive text summarization task. With this actively researched NLP problem, we will be able to review model behavior, performance differences, ROI, and so much more.
By the end of this article, you will learn that GPT-3.5’s Turbo model gives a 22% higher BERT-F1 score with a 15% lower failure rate at 4.8x the cost and 4.5x the average inference time in comparison to GPT-3’s Ada model for abstractive text summarization.
Using GPT Effectively
Suppose you want to use GPT for fast solutions in NLP applications, like translating text or explaining code. Where do you start? Fortunately, there are only three main steps in using GPT for any unique task:
- Picking the right model
- Creating an appropriate prompt
- Using GPT’s API for responses (our code is at the end of this article)
Prior to picking a model, we must first consider a few things: How well does each model work? Which one gives the best ROI? Which one generally performs the best? Which one performs the best on your data?
To narrow down the logistics in choosing a GPT model, we use the CNN-DailyMail text summarization dataset to benchmark and compare the performance of five GPT models: Ada, Babbage, Curie, Davinci, and Turbo. The test split of the dataset contains 11,490 news articles and their respective summaries.
For step two, we generate new summaries with each model using a consistent prompt in the following format:
“Professionally summarize this news article like a reporter with about {word_count_limit} to {word_count_limit+50} words:\n {full_text}”
In practice, it takes some experimentation to refine a prompt that will give subjectively optimal results. By using the same prompt, we can accurately compare model behaviors with one less variable in how each model differs.

In this particular article, we focus on step one, which is picking the right model.
Validating GPT Model Performance
Let’s get acquainted with the GPT models of interest, which come from the GPT-3 and GPT-3.5 series. Each model has a token limit defining the maximum size of the combined input and output, so if, for example, your prompt for the Turbo model contains 2,000 tokens, the maximum output you will receive is 2,096 tokens. For English text, 75 words typically tokenizes into roughly 100 tokens.

We’re currently on the waitlist for GPT-4 access, so we’ll include those models in the future. For now, the main difference between GPT-4 and GPT-3.5 is not significant for basic tasks, but GPT-4 offers a much larger limit for tokens at a much higher price point compared to Davinci.
Performance Metrics of Abstractive Text Summarization
As we all know, metrics help us measure performance. The tables below highlight the standard and custom metrics we use to evaluate models on their text summarization performance:

*We calculate BLEU scores with SacreBLEU and BERT scores with Microsoft’s deberta-xlarge-mnli model.

ROUGE and BLEU measure similarity with word matchings in the ground truths and inferences, while BERT scores consider semantic similarity. The higher the value, the closer the similarity:

Results with Standard Metrics
After we generate new summaries (inferences) per article on each model, we can compare model performance across any type of metric with the ground truths. Let’s look into the summary comparisons and metric plots, ignoring Babbage for more readability.
ROUGE_L and BLEU
In the following example, the original 350-word news article has this summary:
A new report from Suncorp Bank found Australians spent $20 billion on technology in the past year. Men spent twice as much as women on computers, digital accessories, mobile apps, and streaming services. Families with children at home spend 50 per cent more to stay digitally than singles, couples without children and empty nesters. One third of households don’t budget for technology or wildly underestimate how much they will spend.
We get the following ROUGE_L, BLEU, and generated summaries with Davinci and Ada:

You’ll notice that by reading the generated summaries, Davinci does a coherent job of summarizing the content of a larger text. Ada, however, does not provide a summary of the same quality, and the lower values of ROUGE_L and BLEU reflect that lower quality of output.

Distribution of ROUGE_L – Created on Kolena
When we examine the distributions of ROUGE_L and BLEU for each model, we see that Ada has lower metric values, and Turbo has the highest metric values. Davinci falls just behind Turbo in terms of these metrics. As GPT models increase in size, we see a general increase in ROUGE and BLEU scores, too. The greater the value for these metrics, the greater the number of words from the ground truth summary exist in the generated texts. In addition, these larger models produce a more informative summary with fewer grammatical issues.

Distribution of BLEU – Created with Kolena
BERT_F1
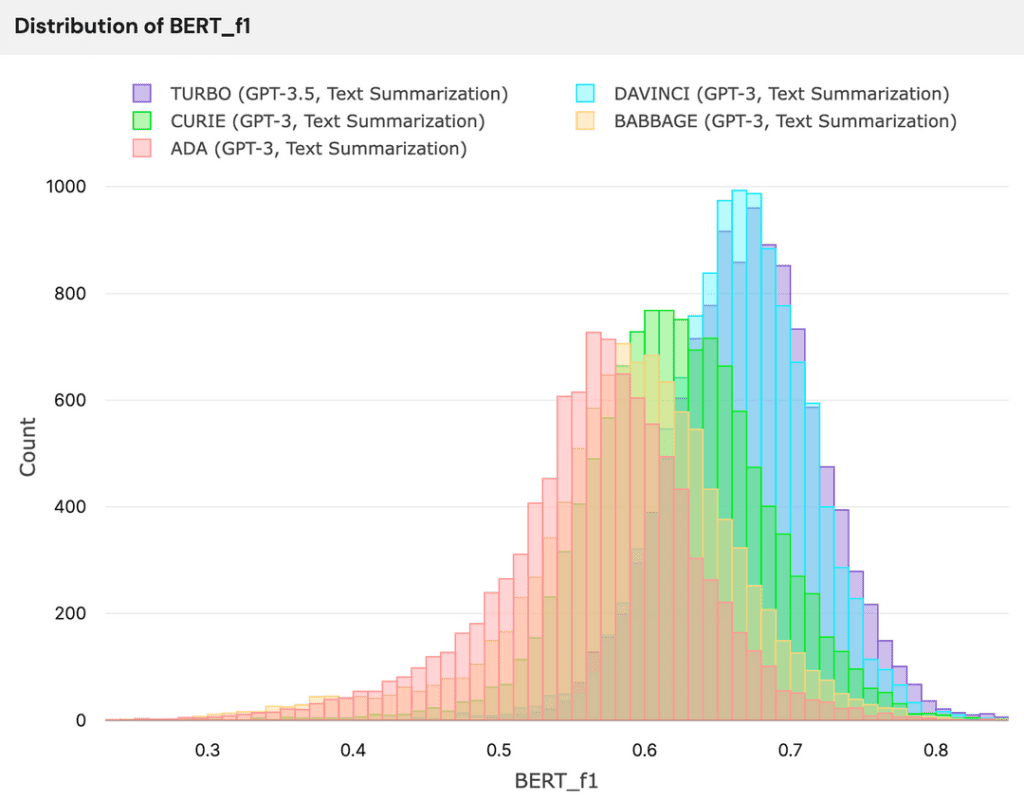
For BERT scores, the same trend is consistent: larger models have better performance in matching key words and semantic meaning from the provided summary. This is evident in how the distribution for larger models shifts to the right, in the direction of higher F1 scores.

Distribution of BERT_F1 – Created with Kolena

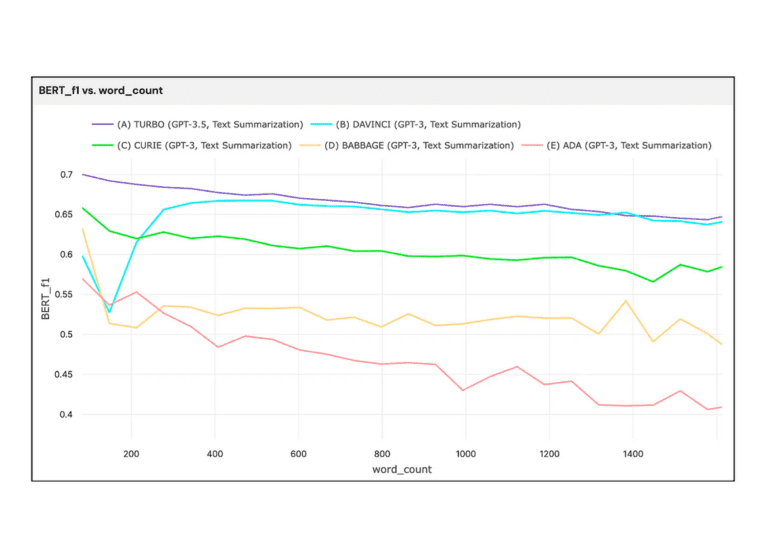
BERT_F1 vs word_count – Created with Kolena
From the plot above, we see that bigger models maintain their performance better than smaller models as text size grows. The larger models remain consistently performant across a wide range of text lengths while the smaller models fluctuate in performance as texts grow longer.
Results with Custom Metrics
Let’s check our custom metrics to see if there’s any reason not to use Turbo or Davinci.

Distribution of API Request Costs – Created with Kolena
From the models’ cost distributions, we learn that Davinci is far more expensive than any other model. Although Davinci and Turbo perform at similar levels, Davinci costs around ten times the cost of Turbo.

Distribution of inf_to_gt_word_count – Created with Kolena
In the figure above, there is a drastic difference in the number of words generated for the same ground truth. Turbo and Davinci consistently provide a summary that is twice the ground truth summary length, whereas other models are very inconsistent. Specifically, some generated summaries from the smaller models are much shorter and some are more than four times as long! Keep in mind that we prompted each model with the same request and word count target per article, but certain models adhered to that restriction while others completely ignored it.

The variance in summary length is a problem for users as this imbalance indicates potential issues with the model or poor performance. In the example above, Curie repeats “number of charitable causes in the past, most notably his work with St. Jude Children’s Research Hospital” at least twice. In comparison to Turbo, Curie’s summary is redundant and suboptimal while costing the same price within a tenth of a cent. Within that small difference, we should note that the cost in generating this particular summary with Curie is double the cost of Turbo since the number of tokens contained in the output was extremely high.
Analysis of Results
After running model evaluations for an hour on Kolena, we can outline and summarize each model’s performance and characteristics as shown below.

We now understand that the larger the model size:
- The more semantically similar the provided and generated summaries are
- The more expensive it is to compute, with the exception of Turbo
- The lower the number of empty summaries
- The slower it is to generate a summary
- The more consistently the model behaves
Ultimately, the Turbo model is the top-performing model offered in the GPT-3/3.5 series, providing the most consistent text similarity scores, all while also being very cost-effective.
Notes for Further Research
Interestingly, given a text to summarize, some models simply refuse to generate output, even though the prompt is within the token limit. Turbo failed on none of the articles, which is a great achievement. However, this might be because Turbo is not as responsive in flagging sensitive content or puts less emphasis in making such considerations. Ada might be less performant, but we should ask OpenAI if it refuses to generate summaries out of ethical consideration or technical limitations. Below is a sample of the top sixteen news articles by BERT_F1 where Ada failed to provide any summary, but Turbo produced decent summaries. It does seem like Ada is less lenient in producing summaries with sensitive content:

Articles Where Ada Fails While Turbo Performs Well – From Kolena
The ground truth summaries from the dataset are not necessarily ideal in content or length. However, we assume ground truth summaries are ideal for the purpose of straightforward performance computations, so model evaluation metrics might indicate that a great model is actually underperforming, even though it produces perfectly valid and detailed summaries. Perhaps some generated summaries are even better than their ground truth counterpart, as shown below:

Conclusion
The world of NLP is rapidly advancing with the introduction of LLMs like GPT. As such models become larger, more complex, and more expensive, it is crucial for developers and users alike to understand their expected performance levels for specific use cases.
Different models may better fit your business requirements, depending on your problem, expectations, and available resources. There is much to consider when picking a single GPT model for your NLP tasks. In the quickly advancing era of LLMs, hopefully the findings outlined in this article give a new perspective on the differences among OpenAI’s models.
Shoutout to Kolena for its amazing platform, where all of these tests, metrics, and plots currently live. Stay tuned for more posts in the future where we may cover prompt engineering, GPT-4 performance, or differences in model behavior by types of content as well!
As promised earlier in this article, our code for reference and all five models’ summaries for every example within this article are all on this page. You can learn more about OpenAI’s API or models in OpenAI’s documentation.